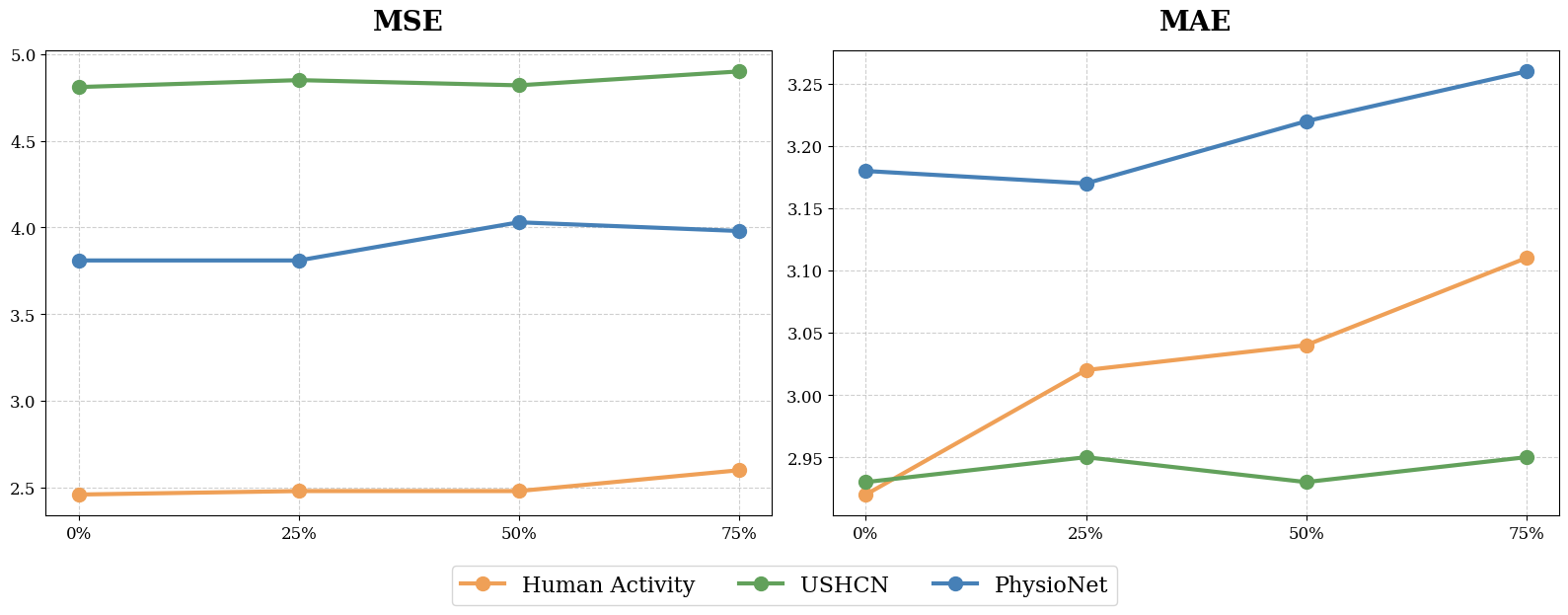
Tokenize. Then aggregate.
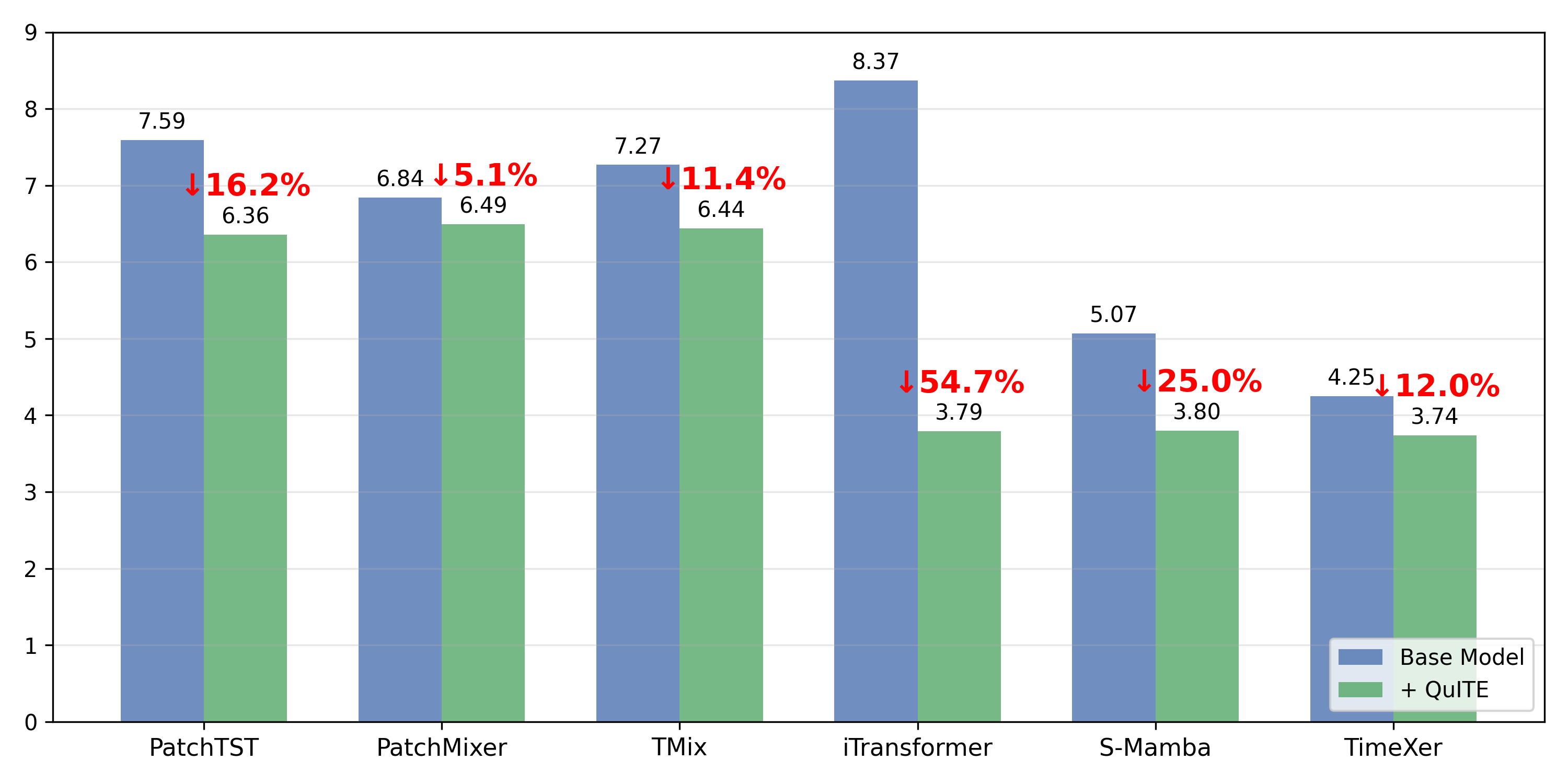
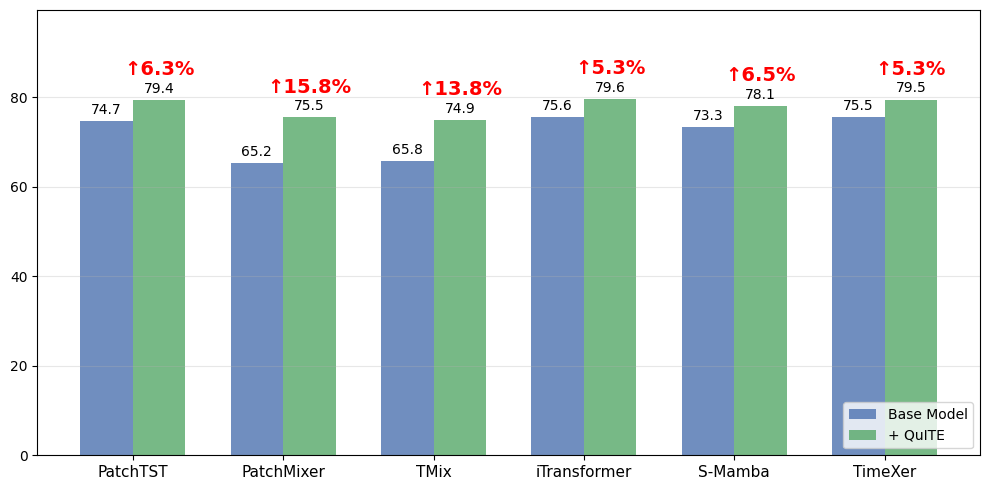
Two stages, one self-attention layer — that's all QuITE adds to the backbone.
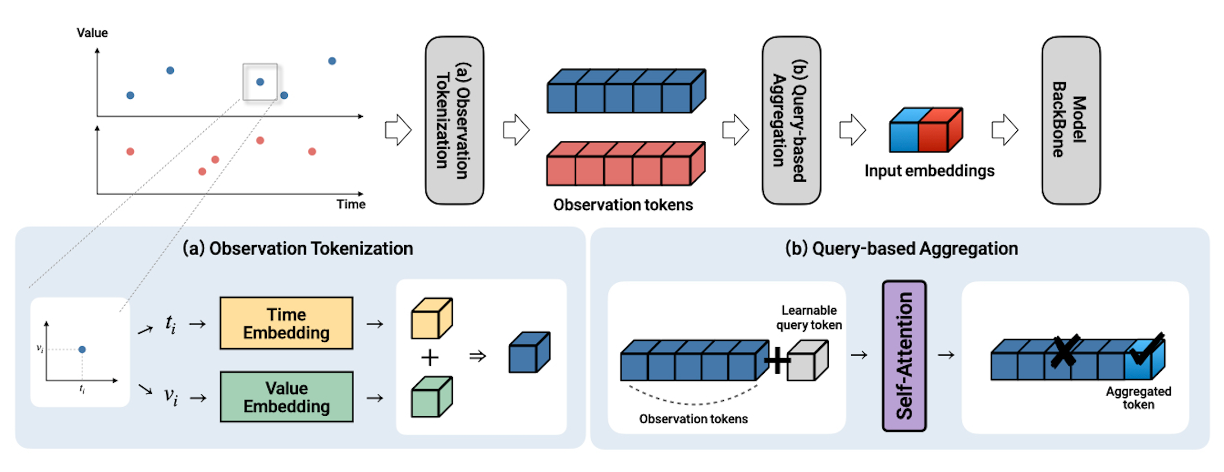
Each observation becomes one token
Every value–time–mask triplet $(x_{n,i}, t_{n,i}, m_{n,i})$ is encoded as the sum of a harmonic time embedding and a learned value projection. No interpolation — the irregular set is preserved exactly.
One learnable query summarizes them all
A learnable query token $\mathbf{q}_n$ is prepended to the observation tokens, and a single masked self-attention layer lets the query summarize all observed entries. Two flavors: variable-level (variate-token models) and patch-level (patch-token models).
QuITE++ — a forecasting architecture built natively around queries
Hierarchical encoder interleaving patch- and variable-level attention, with a cross-attention decoder over future timestamps.
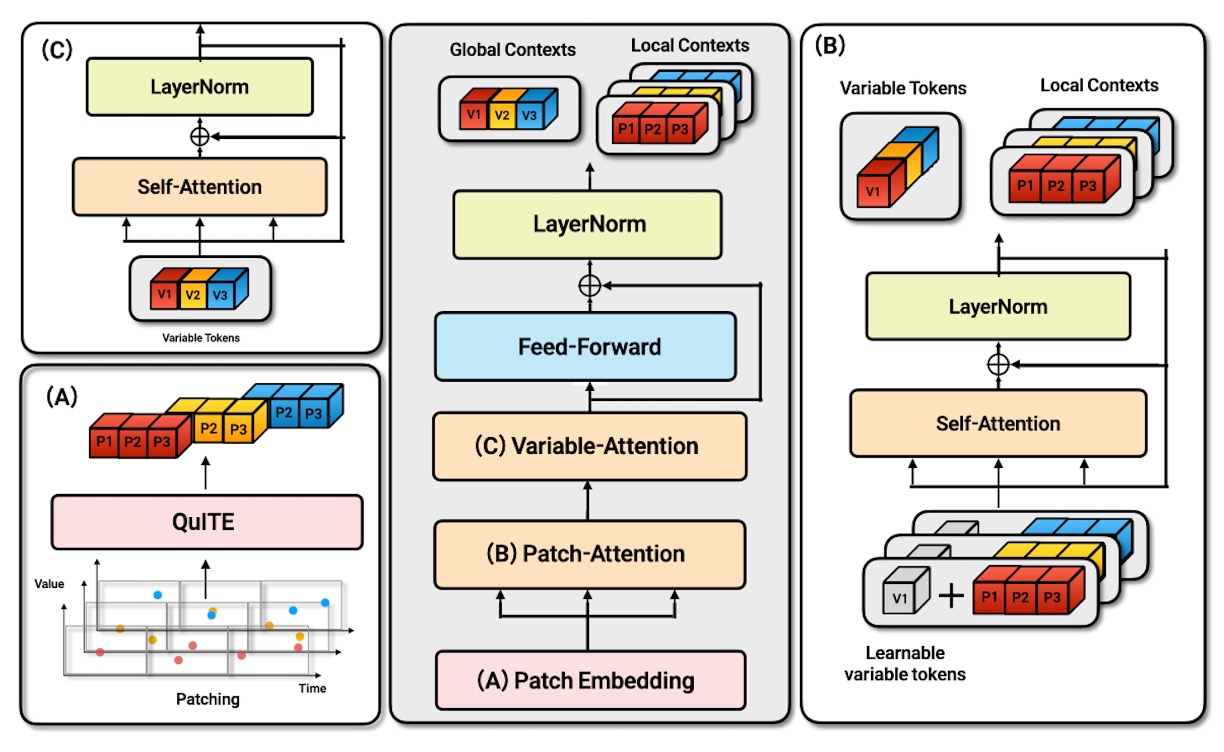
Patch-level attention
Aggregates information across temporal patches within each variable.
Variable-level attention
Models cross-variable dependencies along the variate axis.
Cross-attention decoder
Future time embeddings query the encoder for arbitrary forecast horizons.